Querying data with SPARQL
SPARQL is a query language you can use to get highly customised results sets from statistics.gov.scot. It's the most flexible and powerful way to work with the data.
This guide describes:
- What SPARQL is
- How to get to the SPARQL editor
- Writing SPARQL queries
What is SPARQL?
SPARQL is a query language, designed for querying RDF. SPARQL stands for SPARQL Protocol and RDF Query Language.
SPARQL will look familiar to anyone who has used SQL. Where SQL is for querying relational databases, SPARQL is for querying RDF (or graph) databases.
How to get to the SPARQL editor
On the main page of statistics.gov.scot, in the ‘Data’ tab, inside the ‘Tools’ menu, there is a link to the SPARQL Query console. Clicking this will open the SPARQL console, with a very simple query pre-populated into the editor pane.
Alternatively, this is the address of the SPARQL query console: https://statistics.gov.scot/sparql

Writing SPARQL queries
To be able to write SPARQL queries to get data out of statistics.gov.scot, it is important to understand how the data is structured. Please also read our quick linked data primer.
In this guide, we are only going to look at SELECT queries - to simply return data in tabular format (e.g. downloadable as CSV). There are other SPARQL variants that allow you to retrieve data in graph formats, but these are outside the scope of this guide.
At its heart, a SPARQL SELECT query is simply about pattern matching, using combinations of known-values and variables. The known values can be expressed using URIs (such as <http://royalfamily.com/charles>) or literals (e.g. strings, numbers), and the variables are of the form ?variablename. The simplest SELECT query would look like this:
SELECT ?s ?p ?o
WHERE { ?s ?p ?o }
This would return every single piece of data in the database. Because we’ve used variables in the subject, predicate and object part of the triple, there is nothing to restrict the triples being returned.
Continuing to use the Royal Family example from the Linked Data Primer guide, if we write a query that locks a part of a triple down:
SELECT ?p ?o
WHERE { <http://royalfamily.com/charles> ?p ?o }
Then this will only return those triples where Charles is the subject.
Note: these queries won’t return any data from statistics.gov.scot, as this is made-up data about the Royal Family. (There are some real examples from statistics.gov.scot later on!).
royalFam:charles prop:hasAge 68 . royalFam:charles prop:hasTitle “Prince of Wales” . royalFam:charles prop:hasTitle “Duke of Rothesay” . royalFam:charles prop:livesAt “Clarence House” . royalFam:charles prop:hasEyeColour “Blue” . royalFam:charles prop:isPatron “AgeUK” . royalFam:charles prop:isAuthorOf “The Old Man of Lochnagar” .
If we specify the (made up) hasAge predicate instead:
SELECT ?royal ?age
WHERE { ?royal <http://example.com/hasAge> ?age}
This would return all triples that match that pattern - giving us Charles and Camilla’s age.
royFam:charles 68 . royFam:camilla 69 .
We can also use the results of one triple-pattern match in another:
SELECT ?royal ?title
WHERE { ?royal <http://example.com/hasAge> 68 .
?royal <http://example.com/hasTitle> ?title .
}
This will restrict the results to only those subjects that have an age of 68 (in this case just Charles), and then will return any the object of any triples where the subject is Charles, and the predicate is the Title. So this query would return:
royFam:charles “Prince of Wales” . royFam:charles “Duke of Rothesay” .
And this is the basics of SPARQL querying. We’ve chosen a very simple database for our examples here, to illustrate the principles. In reality, it can be harder to work out how to get what we want out of the database. Thankfully, there are tricks to help guide us.
Querying actual data
When querying the data in statistics.gov.scot - it’s best to use the site as the guide. You could think of statistics.gov.scot as one big documentation site for how to query its data with SPARQL.
Let's walk through an example. Say we are interested in querying information about children’s dental health. Start by navigating to a particular observation on statistics.gov.scot (Find a dataset, get a spreadsheet view, click a cell). e.g: This observation
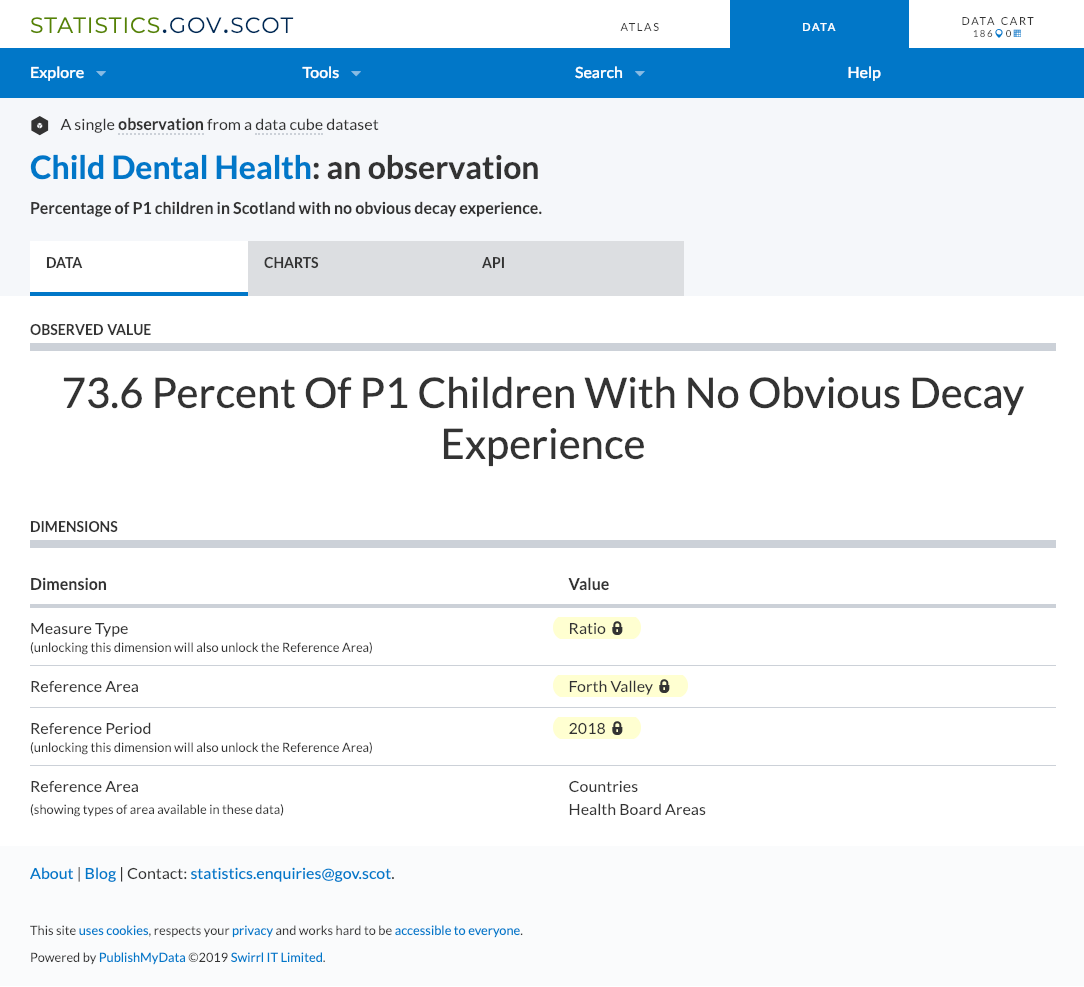
Here we have a specific observation - the percentage of children with no obvious dental decay. The API tab shows the URI of this observation, and a table of all the triples that there are that have this observation as their subject.
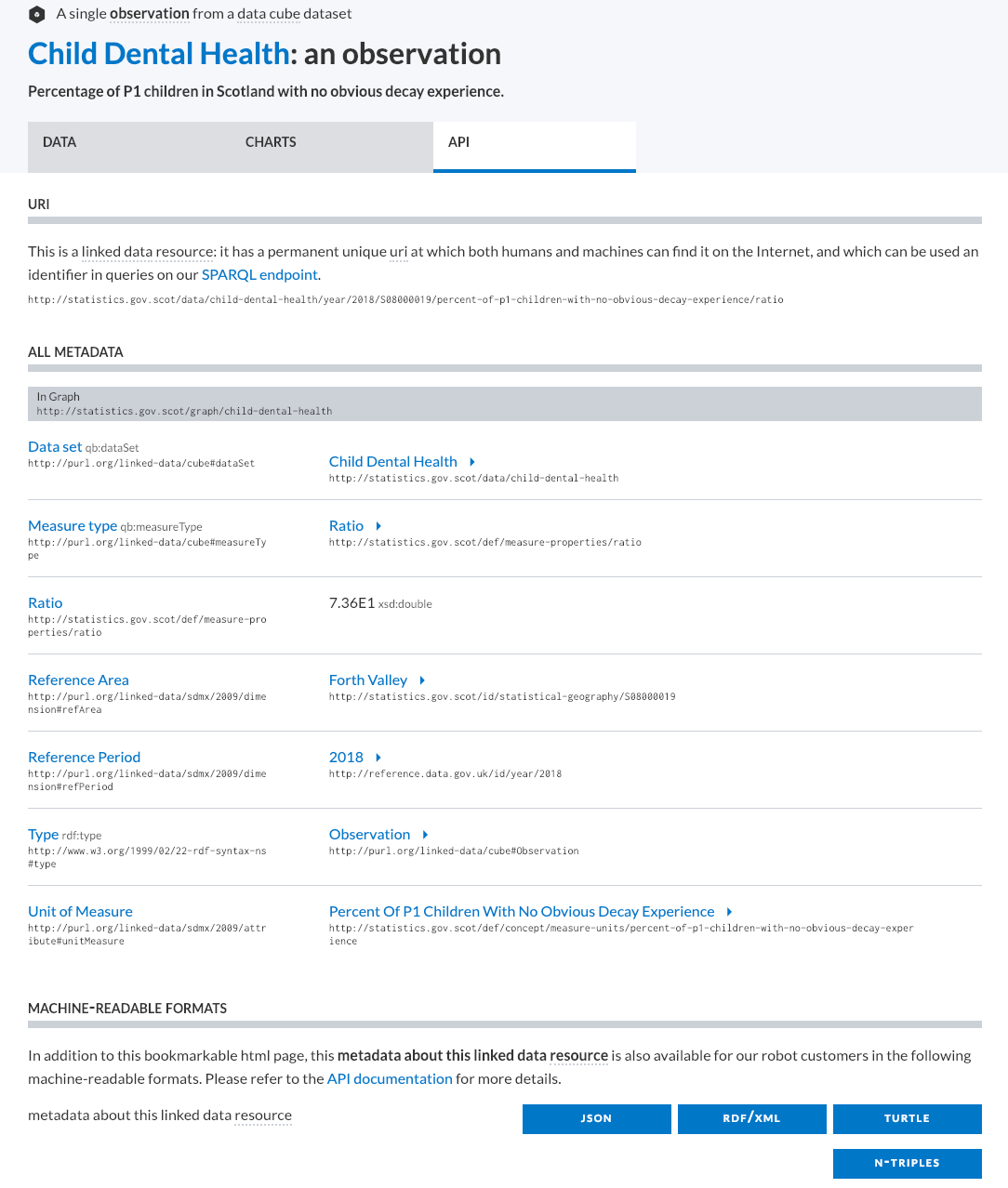
This page is very useful in building SPARQL queries, because it is just a nicely formatted view of the predicate-object pairs for that subject. Another way of representing this is:
Here, we can see that there are triples relating to the area (triple 4 in our table above), the time period (5), and some other information about this observation. If we want to get write a SPARQL query that returns all observations that are about this particular dataset, we can use these URIs to do that.
In the SPARQL editor on statistics.gov.scot, we can type in:
SELECT *
WHERE { ?obs <http://purl.org/linked-data/cube#dataSet> <http://statistics.gov.scot/data/child-dental-health> }
Remember that SPARQL is pattern matching, so this will return all triples that match the specified criteria, and will return, in this case, the subject. When we run the query, we have one column of data returned, headed ‘obs’ containing the URLs of all observations in the child dental health dataset.
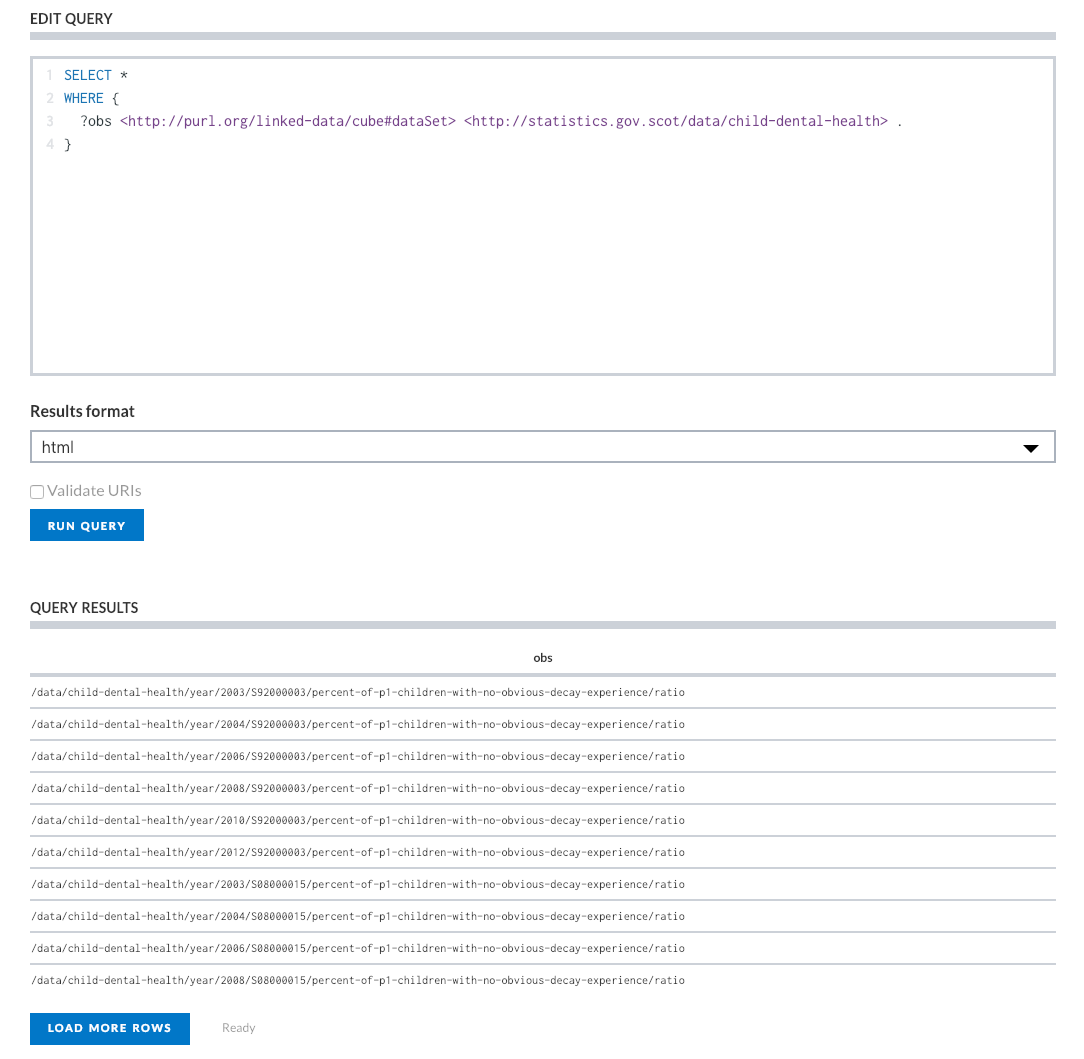
Notice how each row looks identical, but on closer inspection, each URL has a different ‘S08000…’ value (also ‘S92000003’ - Scotland’s code) - these are the Health Board Area codes.
On its own, this isn’t much use. So we can build up the SPARQL query now to give us more information.
SELECT *
WHERE {
?obs <http://purl.org/linked-data/cube#dataSet> <http://statistics.gov.scot/data/child-dental-health>.
?obs <http://purl.org/linked-data/sdmx/2009/dimension#refArea> ?areauri .
?obs <http://purl.org/linked-data/sdmx/2009/dimension#refPeriod> ?perioduri .
?obs <http://statistics.gov.scot/def/measure-properties/ratio> ?value .
}
We have now built up our SPARQL, adding in patterns to match the area, time period and the indicator value for each. We’ve used the first pattern-match statement to get the URL of the observation, and then in subsequent statements we’ve used that variable to return the bits of information that we want.
Notice that each statement in the query is separated by a full-stop (period).
This is what we get:
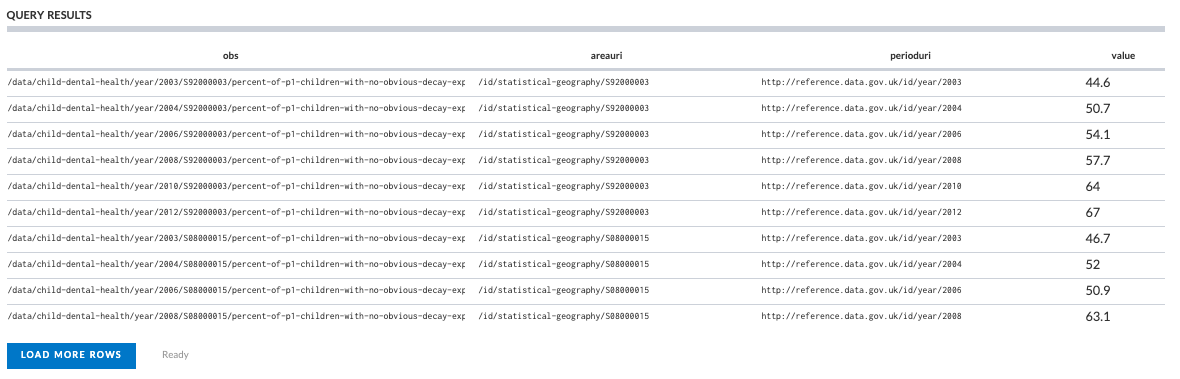
So we’ve got the relevant information being returned by the query, but it still isn’t quite as useful as we’d like it to be. To use these results elsewhere, it would be preferable to have Human-readable labels for the area and the time period, rather than a URL (though there are many situations where having a url is also desirable).
To do this, we need to use another triple, but that is not immediately obvious on the API tab.
The predicate and object for the reference area triple on the API tab shows both the URI (in small grey text) and a human-readable label. Almost everything on statistics.gov.scot has a label. This is stored using the predicate rdfs:label. Updating our query with this new statement:
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT *
WHERE {
?obs <http://purl.org/linked-data/cube#dataSet> <http://statistics.gov.scot/data/child-dental-health> .
?obs <http://purl.org/linked-data/sdmx/2009/dimension#refArea> ?areauri .
?obs <http://purl.org/linked-data/sdmx/2009/dimension#refPeriod> ?perioduri .
?obs <http://statistics.gov.scot/def/measure-properties/ratio> ?value .
?areauri rdfs:label ?areaname .
?perioduri rdfs:label ?periodname .
}
Gives us labels in the results:
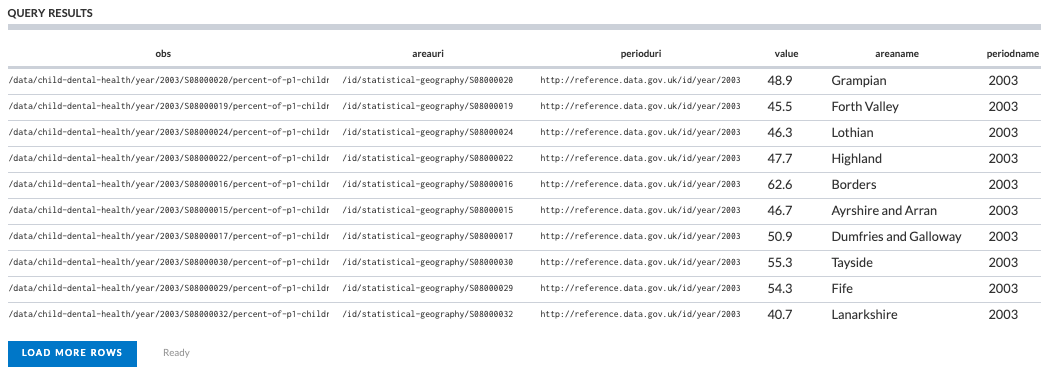
Notice that in the new query, we chose to add a new line at the top:
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
This tells the query that wherever we use `rdfs` in the query, it’s actually shorthand for http://www.w3.org/2000/01/rdf-schema#, and saves space (and noise) in the queries.
The final step is to only return the fields that we actually want. To do this, we change the 'SELECT *' statement, which means 'select everything', to only the fields that we want:
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?areaname ?periodname ?value
WHERE {
?obs <http://purl.org/linked-data/cube#dataSet> <http://statistics.gov.scot/data/child-dental-health> .
?obs <http://purl.org/linked-data/sdmx/2009/dimension#refArea> ?areauri .
?obs <http://purl.org/linked-data/sdmx/2009/dimension#refPeriod> ?perioduri .
?obs <http://statistics.gov.scot/def/measure-properties/ratio> ?value .
?areauri rdfs:label ?areaname .
?perioduri rdfs:label ?periodname .
}
Which gives this:
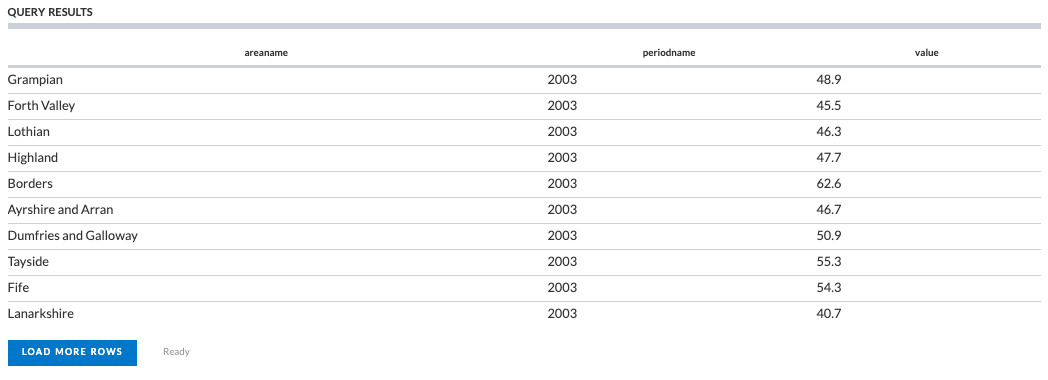
We can then download these results as a CSV file, by changing the results format in the dropdown below the query editing panel, or we can use the SPARQL query itself in an API call. To find out more about this, see the Using APIs user guides.
For more information about SPARQL (including other operations such as sorting, grouping, aggregations, and the other types of query) see the official W3C documentation
To continue exploring our datasets, return to statistics.gov.scot