Understanding the data structure
To be able to make use of the advanced querying on statistics.gov.scot, it is important to first understand how the data is structured. This guide describes:
- What Linked Data is
- Understanding the structure of Linked Data
What is Linked Data?
The simplest way of defining Linked Data is that it is “Data that can be linked to”. In practice, this means that wherever possible, any data point contained in a Linked Dataset should have a unique identifier which is a URL. Doing this means that the data point can be browsed to using a web browser (if a human-readable web-page has been created). It also means that the data point can be referenced by other Linked Data sets.
This makes it very powerful for connecting datasets, and for providing links to data sources.
Understanding the structure of Linked Data
The basic principle behind the way everything is stored on statistics.gov.scot is that the datastore is made up of millions of statements, or ‘triples’ - a combination of three bits of information that form a subject - predicate - object arrangement.
This concept is best described in a series of diagrams. This is what a triple looks like:
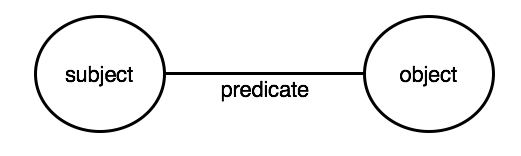
So we have two nodes (the subject and object) joined by an edge (the predicate). To make this make a little more sense, we can plug some real data into it:
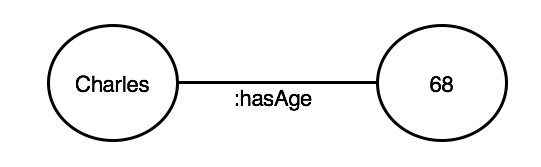
Here we can see that the subject - predicate - object arrangement is actually a statement which says ‘Charles has age 68’. In RDF, this looks like this:
<http://royalfamily.com/charles> <http://example.com/properties/hasAge> 68
( Note: if we were to model this as linked data for-real, we'd take more care with the URI patterns and choose the vocabularies carefully)
Now we can use lots of these triples to describe Charles in greater detail:

So we can see that Charles has blue eyes, lives at Clarence House, and has a couple of titles (in our made-up model). In RDF, this looks like this:
@prefix prop: <http://example.com/properties/> @prefix royalFam: <http://royalfamily.com/> royalFam:charles prop:hasAge68 . royalFam:charles prop:hasTitle “Prince of Wales” . royalFam:charles prop:hasTitle “Duke of Rothesay” . royalFam:charles prop:livesAt “Clarence House” . royalFam:charles prop:hasEyeColour “Blue” . royalFam:charles prop:isPatron “AgeUK” . royalFam:charles prop:wrote “The Old Man of Lochnagar” .
The two ‘@prefix’ lines at the top of the RDF are a form of shorthand, saying everywhere where prop appears, that means <http://example.com/properties/>.
We can see that this is a list of triples, where Charles is the subject of each.
A graph is a collection of nodes and edges, and this is a very simple graph. We can complicate it slightly by adding in another subject:
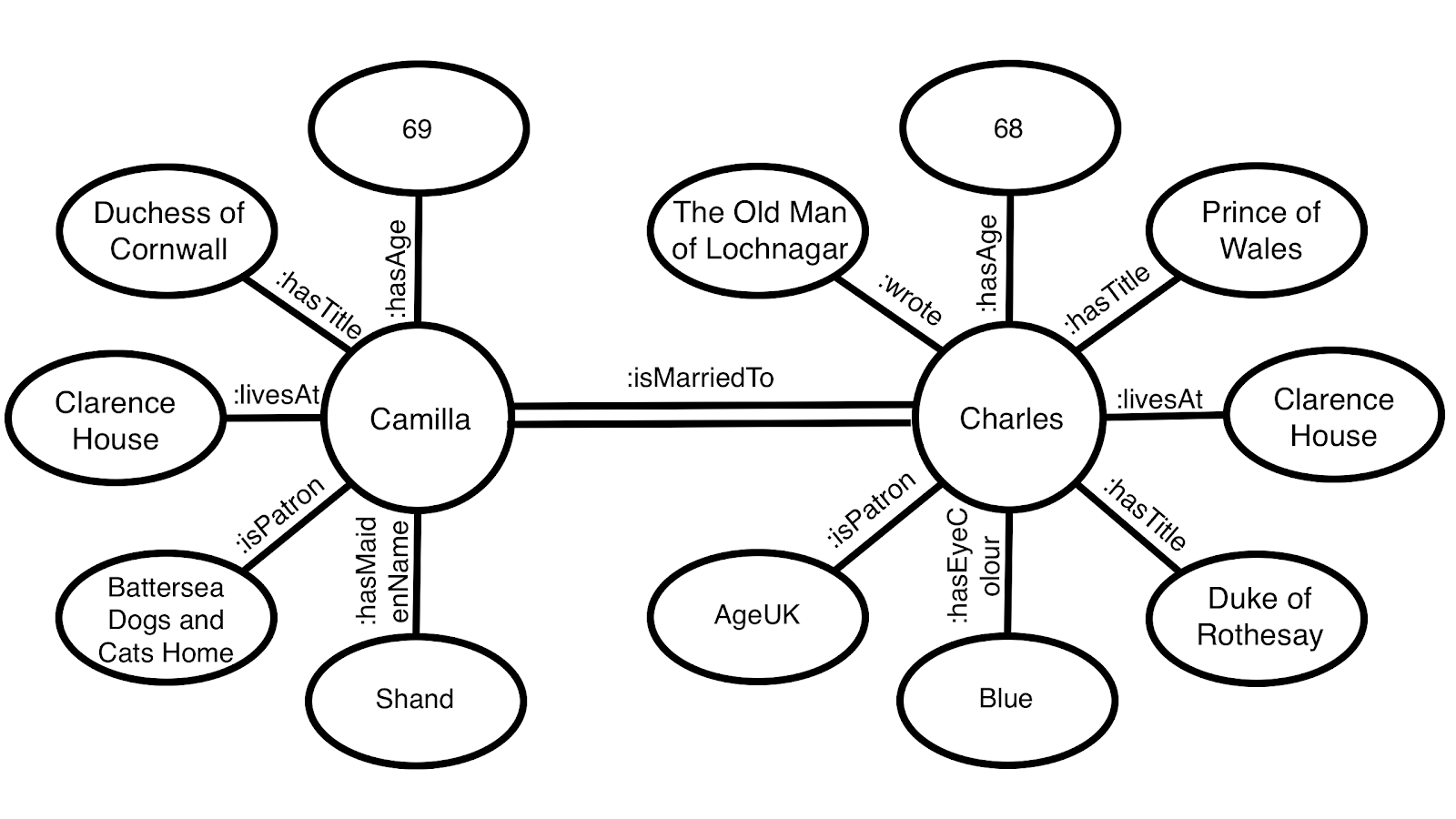
And here’s the RDF for this:
@prefix prop: <http://example.com/properties/> @prefix royFam: <http://royalfamily.com/> royFam:charles prop:hasAge 68 . royFam:charles prop:hasTitle “Prince of Wales” . royFam:charles prop:hasTitle “Duke of Rothesay” . royFam:charles prop:livesAt “Clarence House” . royFam:charles prop:hasEyeColour “Blue” . royFam:charles prop:isPatron “AgeUK” . royFam:charles prop:wrote “The Old Man of Lochnagar” . royFam:charles prop:isMarriedTo royFam:camilla . royFam:camilla prop:hasAge 69 . royFam:camilla prop:hasMaidenName “Shand” . royFam:camilla prop:isPatron “Battersea Dogs & Cats Home”. royFam:camilla prop:livesAt “Clarence House” . royFam:camilla prop:hasTitle “Duchess of Cornwall” . royFam:camilla prop:isMarriedTo royFam:charles .
And so on, and so on. This is essentially what the contents of the statistics.gov.scot looks like - with millions of these triples representing all the different pieces of information on there. This means that the structure of the database is contained within the data - no need for complex database schema.
To continue exploring our datasets, return to statistics.gov.scot